
In February 2024, the research paper titled ” Enhancing context models for point cloud geometry compression with context feature residuals and multi-loss”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, Mr Chang Sun and others from Shandong University and De Montfort University, was accepted for publication in IEEE Journal on Emerging and Selected Topics in Circuits and Systems. This paper focuses on the development of a general method to enhance context models for geometry point cloud compression.
In point cloud geometry compression, context models usually use the one-hot encoding of node occupancy as the label, and the cross-entropy between the one-hot encoding and the probability distribution predicted by the context model as the loss function. However, this approach has two main weaknesses. First, the differences between contexts of different nodes are not significant, making it difficult for the context model to accurately predict the probability distribution of node occupancy. Second, as the one-hot encoding is not the actual probability distribution of node occupancy, the cross-entropy loss function is inaccurate. To address these problems, we propose a general structure that can enhance existing context models rather than proposing a special network.
(1) To enhance the differences between contexts, we propose to include context feature residuals of adjacent contexts into the context models. Furthermore, we use the cosine similarity and the Euclidean distance to calculate the inter-class differences in context.
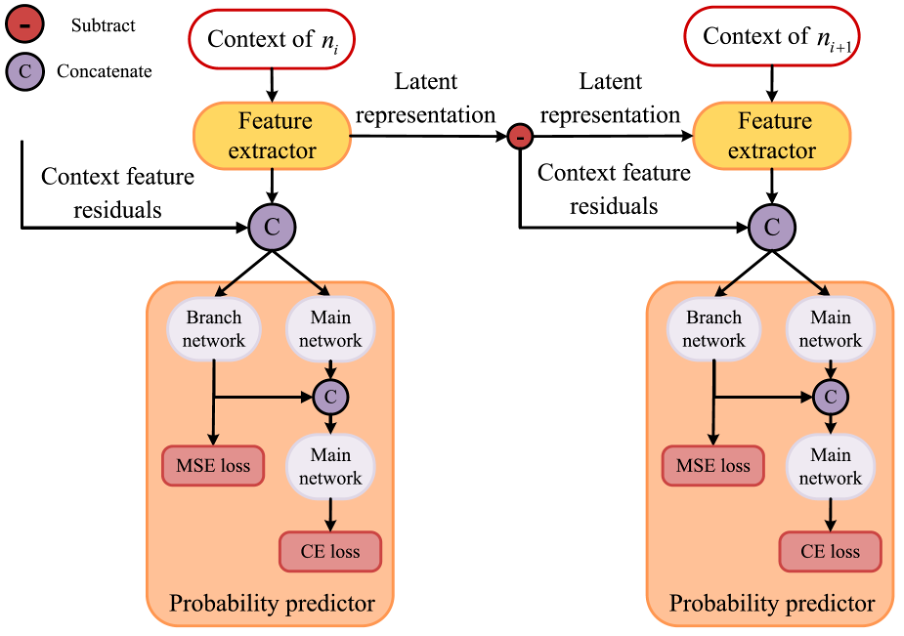
(2) We improve the performance of the context models by adding an MLP branch that directly predicts the node occupancy instead of the probability distribution. The loss function of this branch is the mean squared error (MSE) between its output and the actual node occupancy. Since the node occupancy is an accurate label, this branch introduces accurate gradients during the training of the context model. At the same time, the output of this branch will also serve as a feature to assist the training of the main network.
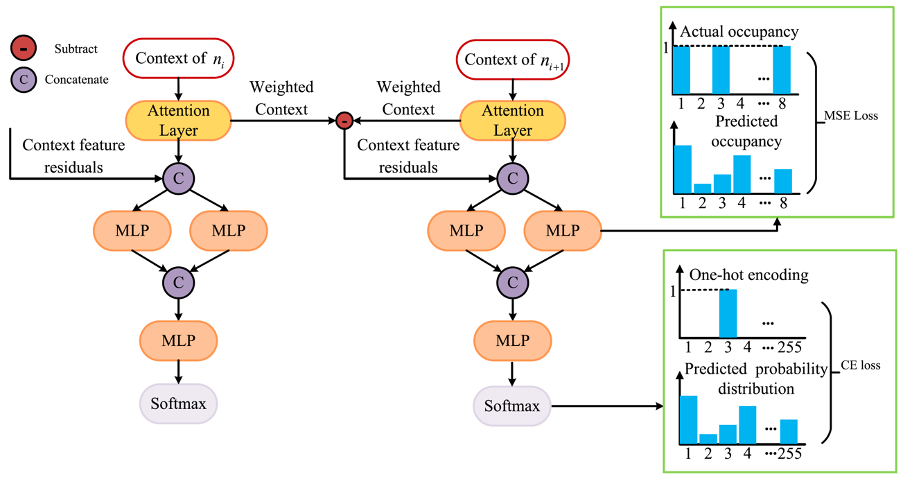
The effectiveness of our proposed approach is demonstrated by applying it to two state-of-the-art models: an octree-based one (OctAttention [1]) and a voxel-based one (VoxelDNN [2]). Experimental results show that our method can reduce the bitrate in geometry point cloud encoding without significantly increasing time complexity.
Reference:
[1] C. Fu, G. Li, R. Song, W. Gao, and S. Liu, “OctAttention: Octree-based large-scale contexts model for point cloud compression,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 625–633.
[2] D. T. Nguyen, M. Quach, G. Valenzise, and P. Duhamel, “Learning-based lossless compression of 3D point cloud geometry,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Toronto, ON, Canada, Jun. 2021, pp. 4220–4224.