
In November 2024, the research paper titled “3D-MSFC: A 3D multi-scale features compression method for object detection”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, Dr Hossein Malekmohamadi and others from Shandong University, was accepted for publication in Displays. This paper focuses on the development of a novel learnable 3D multi-scale sparse feature compression method for 3D object detection tasks.
As machine vision tasks rapidly evolve, a new concept of compression, namely video coding for machines (VCM), has emerged. However, current VCM methods are only suitable for 2D machine vision tasks. With the popularisation of autonomous driving, the demand for 3D machine vision tasks has significantly increased, leading to an explosive growth in LiDAR data that requires efficient transmission. To address this need,
(1) We proposed a novel point cloud coding for machines (PCCM) method, namely 3D-MSFC, to compress and reconstruct 3D multi-scale sparse features using a learnable neural network for 3D machine vision tasks.
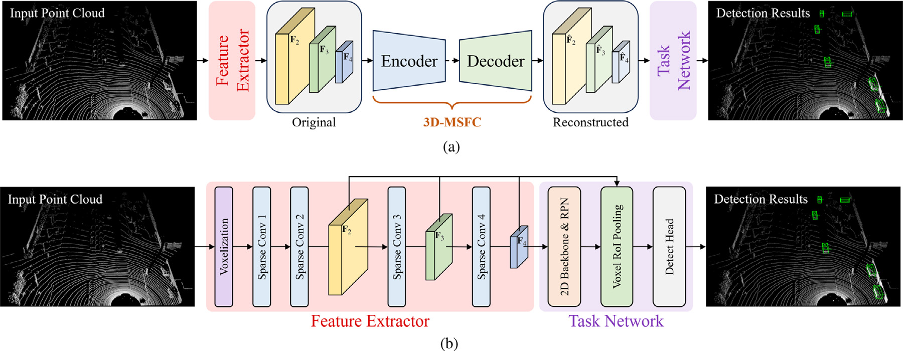
(2) We analysed the importance of each scale of the 3D multi-scale sparse features in terms of object detection accuracy. To cater to various application scenarios, we designed two coding schemes: 3D-MSFC and 3D-MSFC-L, offering multiple choices.
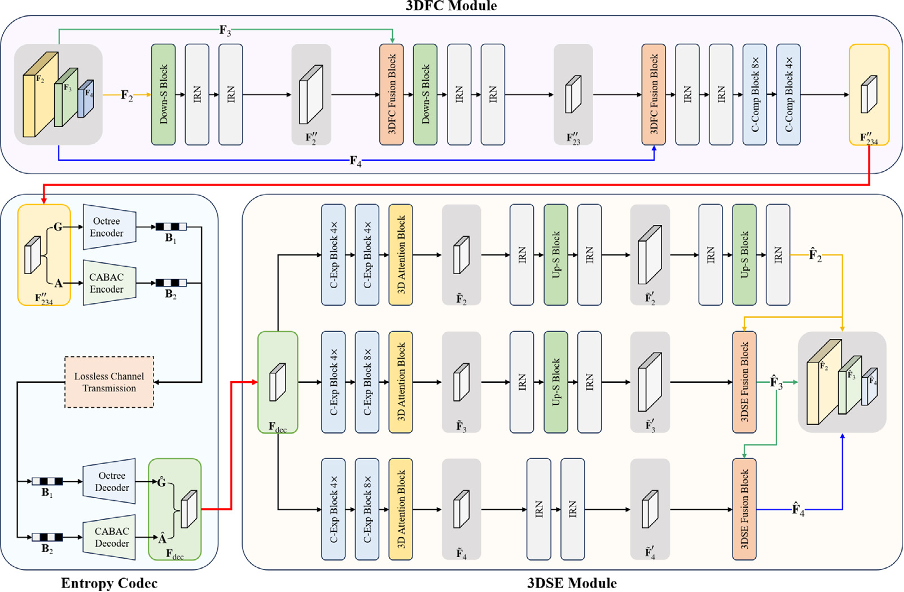
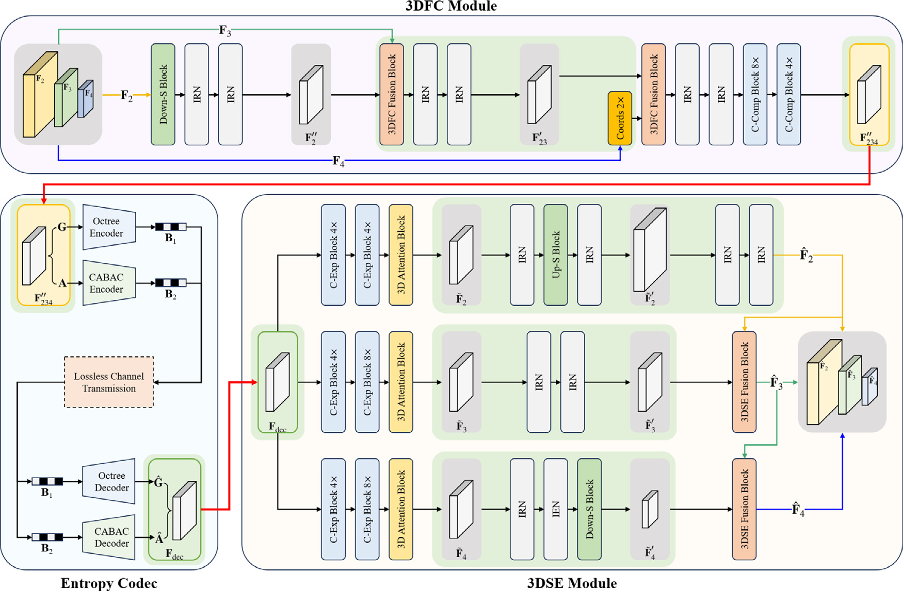
From the rate-accuracy (R-A) curves, we can see that at extremely low kbpe, our proposed method maintains stable detection performance without significant degradation. In contrast, the CTA method shows a significant degradation in detection performance, indicating that the proposed 3D-MSFC significantly outperforms the existing CTA method at extremely low kbpe.
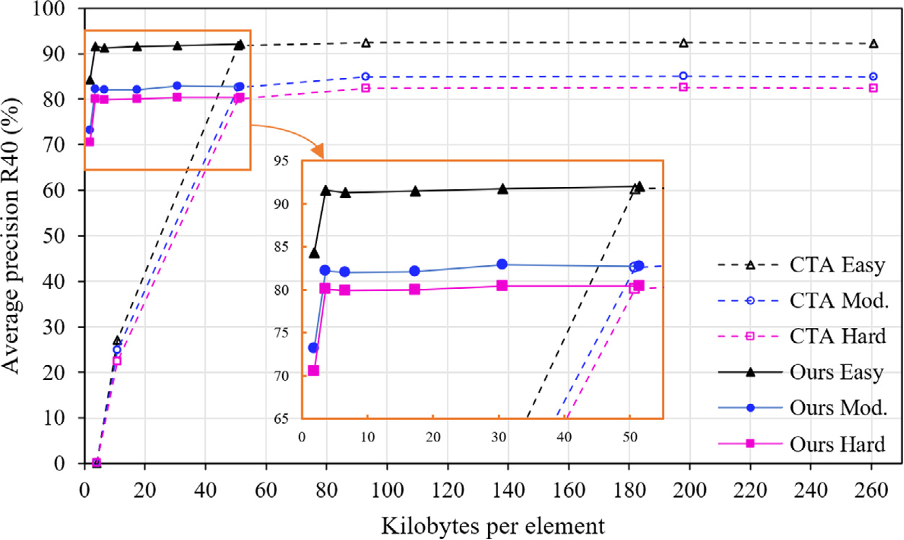
Experimental results demonstrate that 3D-MSFC achieves less than a 3% degradation in object detection accuracy at a compression ratio of 2796×. Furthermore, its low-profile variant, 3D-MSFC-L, achieves less than a 2% degradation in accuracy at a compression ratio of 463×. The above results indicate that our proposed method can provide an ultra-high compression ratio while ensuring no significant drop in accuracy, greatly reducing the amount of data required for transmission during each detection. This can significantly lower bandwidth consumption and save substantial costs in application scenarios such as smart cities.
Reference:
K. Mammou, P.A. Chou, D. Flynn, M. Krivokuca, O. Nakagami, T. Sugio, G-PCC codec description v2, ISO/IEC JTC1/SC29/WG11 N 18189, 2019, p. 2019.