Professor Hui Yuan and Dr Xin Lu are guest editing the themed Issue on ‘Advances in 3D point cloud processing and applications’ for IET Image Processing (submission deadline 1st July 2025).
The full call for papers can be found here: homepage.
We would be grateful for your contribution to this special issue. If you are interested in contributing, please contact me, Dr Xin Lu at at xin dot lu at dmu dot ac dot uk.
In November 2024, the research paper titled “3D-MSFC: A 3D multi-scale features compression method for object detection”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, Dr Hossein Malekmohamadi and others from Shandong University, was accepted for publication in Displays. This paper focuses on the development of a novel learnable 3D multi-scale sparse feature compression method for 3D object detection tasks. As machine vision tasks rapidly evolve, a new concept of compression, namely video coding for machines (VCM), has emerged. However, current VCM methods are only suitable for 2D machine vision tasks. With the popularisation of autonomous driving, the demand for 3D machine vision tasks has significantly increased, leading to an explosive growth in LiDAR data that requires efficient transmission. To address this need,
(1) We proposed a novel point cloud coding for machines (PCCM) method, namely 3D-MSFC, to compress and reconstruct 3D multi-scale sparse features using a learnable neural network for 3D machine vision tasks.
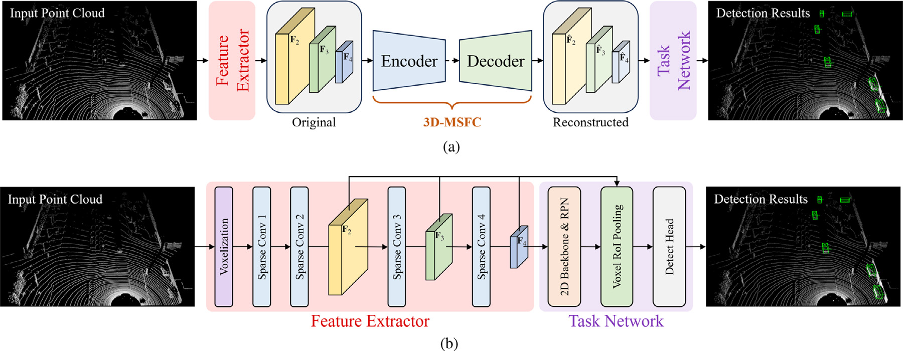
Figure 1: 3D object detection network partitioning and deployment of 3D-MSFC. (a) Framework of the proposed 3D-MSFC, (b) Voxel R-CNN network partitioning.
(2) We analysed the importance of each scale of the 3D multi-scale sparse features in terms of object detection accuracy. To cater to various application scenarios, we designed two coding schemes: 3D-MSFC and 3D-MSFC-L, offering multiple choices.
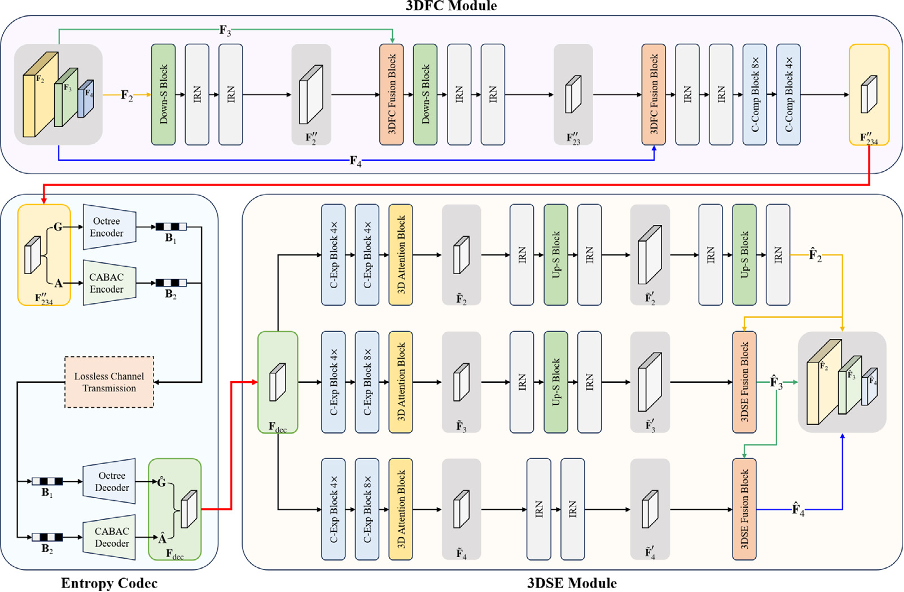
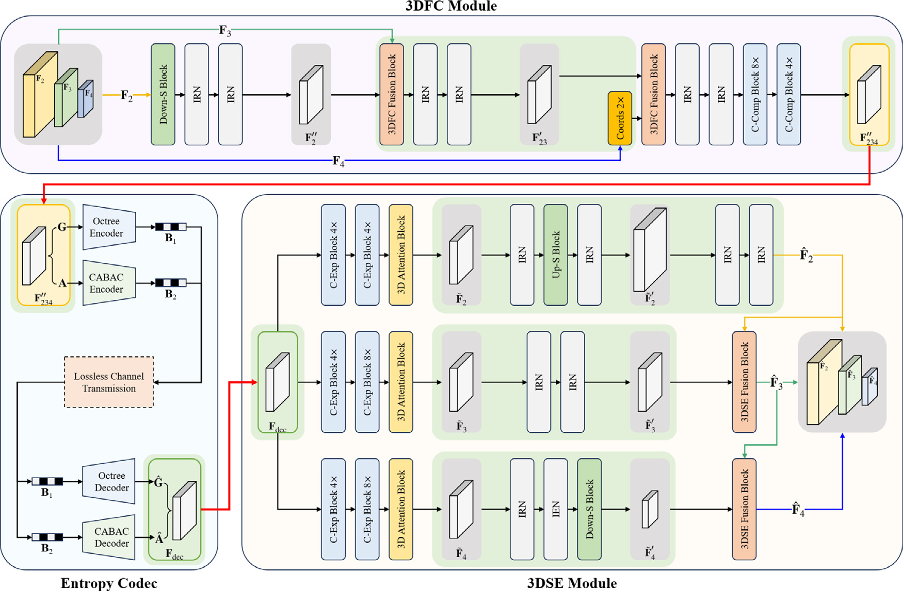
Figure 2: Detailed architecture of 3D-MSFC.Figure 3: Detailed architecture of 3D-MSFC-L.
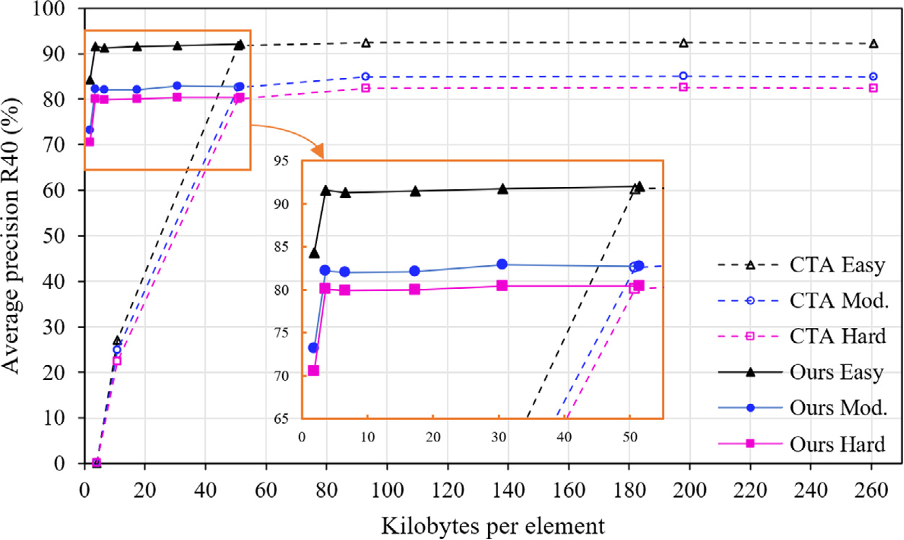
From the rate-accuracy (R-A) curves, we can see that at extremely low kbpe, our proposed method maintains stable detection performance without significant degradation. In contrast, the CTA method shows a significant degradation in detection performance, indicating that the proposed 3D-MSFC significantly outperforms the existing CTA method at extremely low kbpe.
Figure 4: R-A curves of CTA and 3D-MSFC.
Experimental results demonstrate that 3D-MSFC achieves less than a 3% degradation in object detection accuracy at a compression ratio of 2796×. Furthermore, its low-profile variant, 3D-MSFC-L, achieves less than a 2% degradation in accuracy at a compression ratio of 463×. The above results indicate that our proposed method can provide an ultra-high compression ratio while ensuring no significant drop in accuracy, greatly reducing the amount of data required for transmission during each detection. This can significantly lower bandwidth consumption and save substantial costs in application scenarios such as smart cities.
Reference: K. Mammou, P.A. Chou, D. Flynn, M. Krivokuca, O. Nakagami, T. Sugio, G-PCC codec description v2, ISO/IEC JTC1/SC29/WG11 N 18189, 2019, p. 2019.
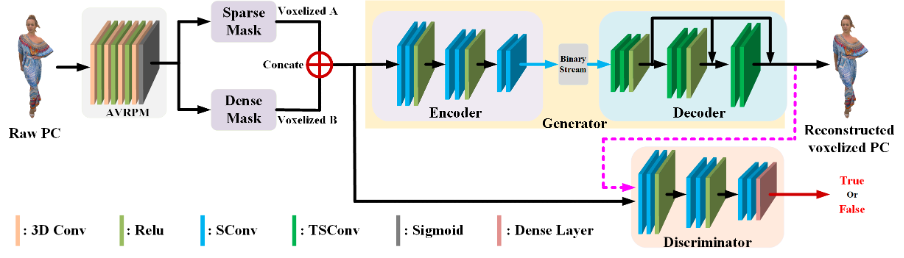
In July 2024, the research paper titled “PCAC-GAN: a sparse-tensor-based generative adversarial network for 3D point cloud attribute compression”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, Mr Xiaolong Mao and others from De Montfort University and Peking University, was accepted for publication in Computational Visual Media. This paper focuses on the development of a novel deep learning-based point cloud attribute compression method that uses a generative adversarial network (GAN) with sparse convolution layers. Learning-based methods have proven successful in compressing the geometry information of point clouds. However, the existing learning-based methods are still not as effective as G-PCC, the current state-of-the-art method. To address this challenge, (1) We propose a novel approach for compressing 3D point cloud attributes using a GAN consisting of sparse convolution layers. To the best of our knowledge, this is the first time GANs have been applied to point cloud attribute compression.
Figure 1: PCAC-GAN architecture. The network consists of AVRPM and a GAN. “Concate” means concatenating two voxelized point clouds with different resolutions. “SConv” and “TSConv” stand for sparse convolution and transposed sparse convolution, respectively.
(2) We propose a novel multi-scale transposed sparse convolutional decoder that contributes to achieving a higher compression quality and ratio in learning-based compression systems while maintaining reasonable computational complexity. (3) We develop an adaptive voxel resolution partitioning module (AVRPM) to partition the input point cloud into blocks with adaptive voxel resolutions. This feature enables AVRPM to effectively process point cloud data
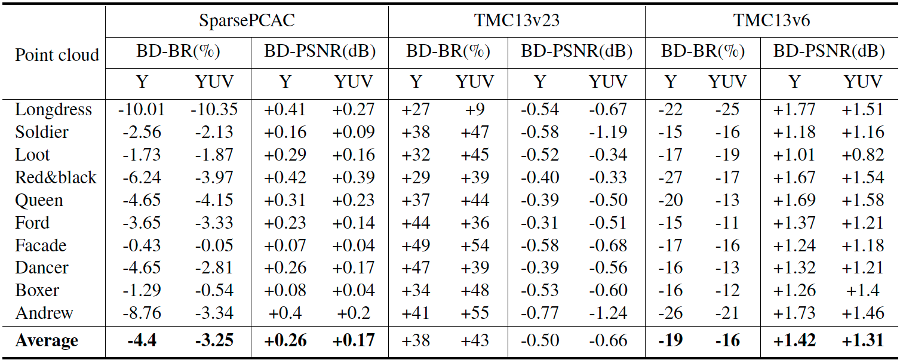
Table 1: BD-BR(%) and BD-PSNR (dB) of the proposed method (test codec) vs. SparsePCAC, TMC13v23, and TMC13v6 (reference codecs). The BD values indicate an increase (+) or decrease (-) in PSNR or BR of the test codec compared to the reference codec
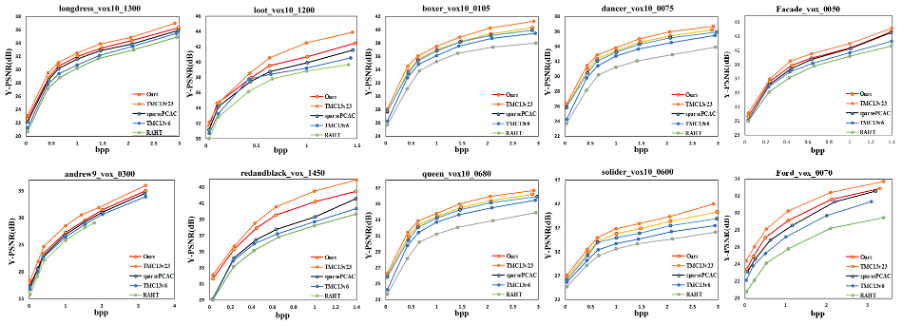
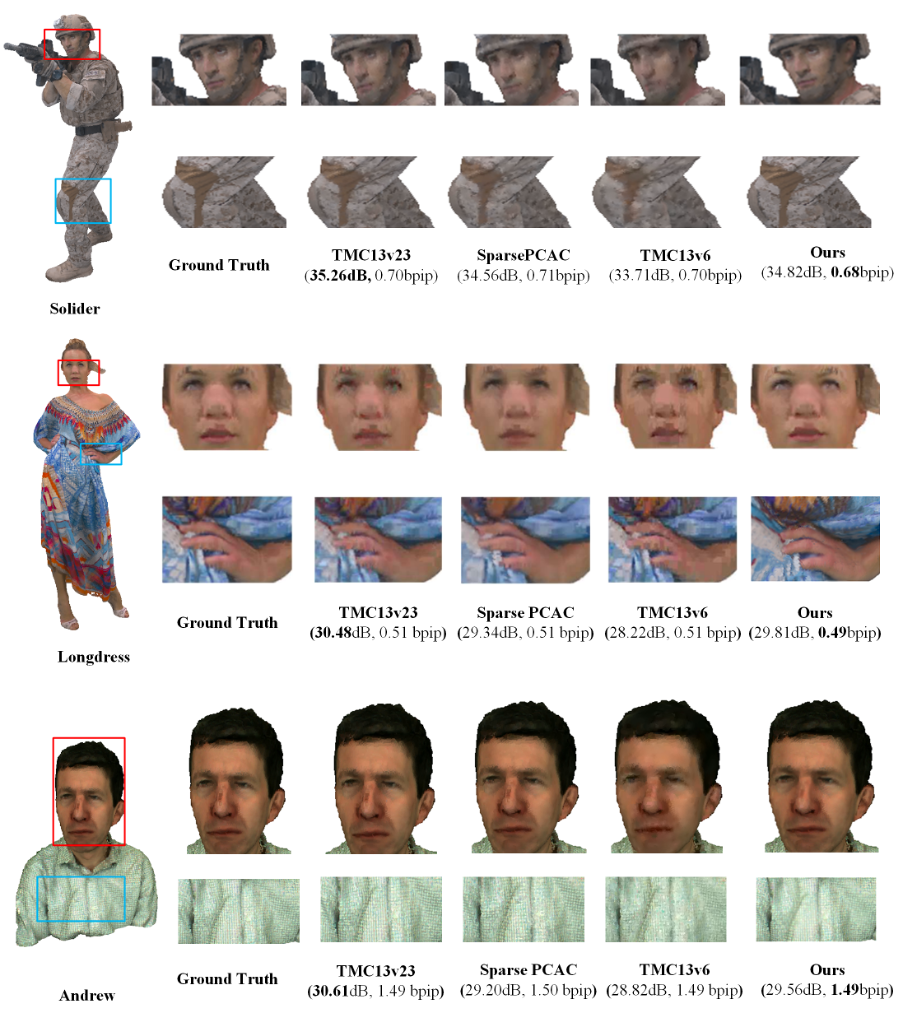
Experimental results demonstrate our method outperformed SparsePCAC [1] and TMC13v6 in terms of BDBR, BDPSNR, and subjective visual quality. While our method had inferior BD-BR and BD-PSNR performance compared to TMC13v23, it offered a better visual reconstruction quality. However, it should be noted that making a direct comparison with TMC13v23 is not entirely fair since our method uses a generative approach, placing it at a disadvantage in the comparison. This disadvantage arises due to the inherent differences in complexity and objectives between generative methods and conventional coding methods, which may affect both compression efficiency and assessment of generated content quality. We anticipate that with further improvements to filtering and cross-scale correlation for prediction, our method will outperform TMC13v23.
Figure 2: Y-PSNR vs. bitrate in bits per input point (bpip).Figure 3: Qualitative visualization of the reconstructed “Longdress” and “Solider” for the proposed method (Ours), SparsePCAC, TMC13v23, and TMC13v6.
Overall, the proposed PCAC-GAN model shows considerable potential in improving the efficiency of point cloud attribute compression. Our innovative use of GANs and sparse convolution layers may open up new possibilities for tackling the challenges associated with point cloud attribute compression.
Reference: [1] Wang J, Ma Z. Sparse tensor-based point cloud attribute compression. 2022 IEEE 5th International Conference on Multimedia Information Processing and Retrieval (MIPR), 2022: 59–64.
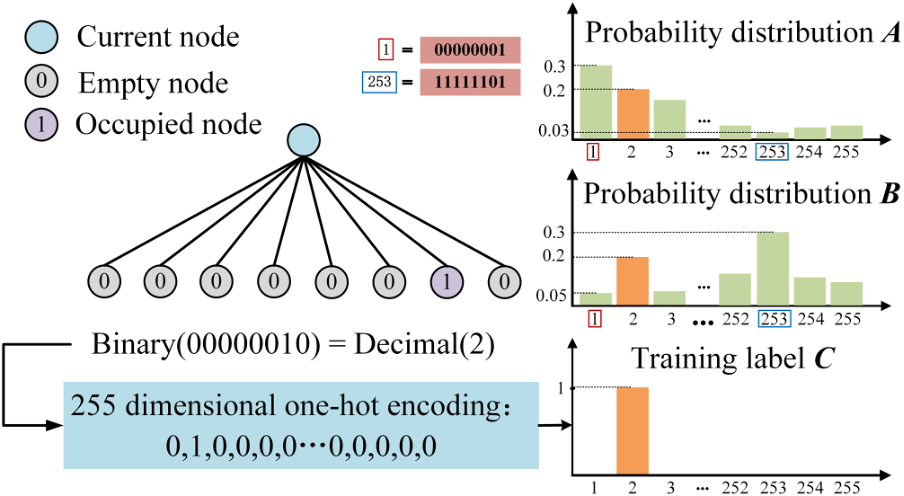
In July 2024, the research paper titled “Enhancing octree-based context models for point cloud geometry compression with attention-based child node number prediction”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, Mr Chang Sun, Mr Xiaolong Mao and others from De Montfort University, was accepted for publication in IEEE Signal Processing Letters. This paper focuses on the development of an attention-based child node number prediction (ACNP) module to enhance octree-based context models, with the aim of improving coding efficiency for point cloud geometry compression. In point cloud geometry compression, most octree-based context models use the cross-entropy between the one-hot encoding of node occupancy and the probability distribution predicted by the context model as the loss. This approach converts the problem of predicting the number (a regression problem) and the position (a classification problem) of occupied child nodes into a 255-dimensional classification problem. As a result, it fails to accurately measure the difference between the one-hot encoding and the predicted probability distribution. In this paper, we propose an attention-based module aimed at enhancing learning-based context models in octree-based geometry compression by directly predicting the number of occupied nodes. 1) We analyse why the cross-entropy loss based on one-hot encoding fails to measure the difference between the label and the probability distribution predicted by the context models.
Figure 1: Problem of cross-entropy loss.
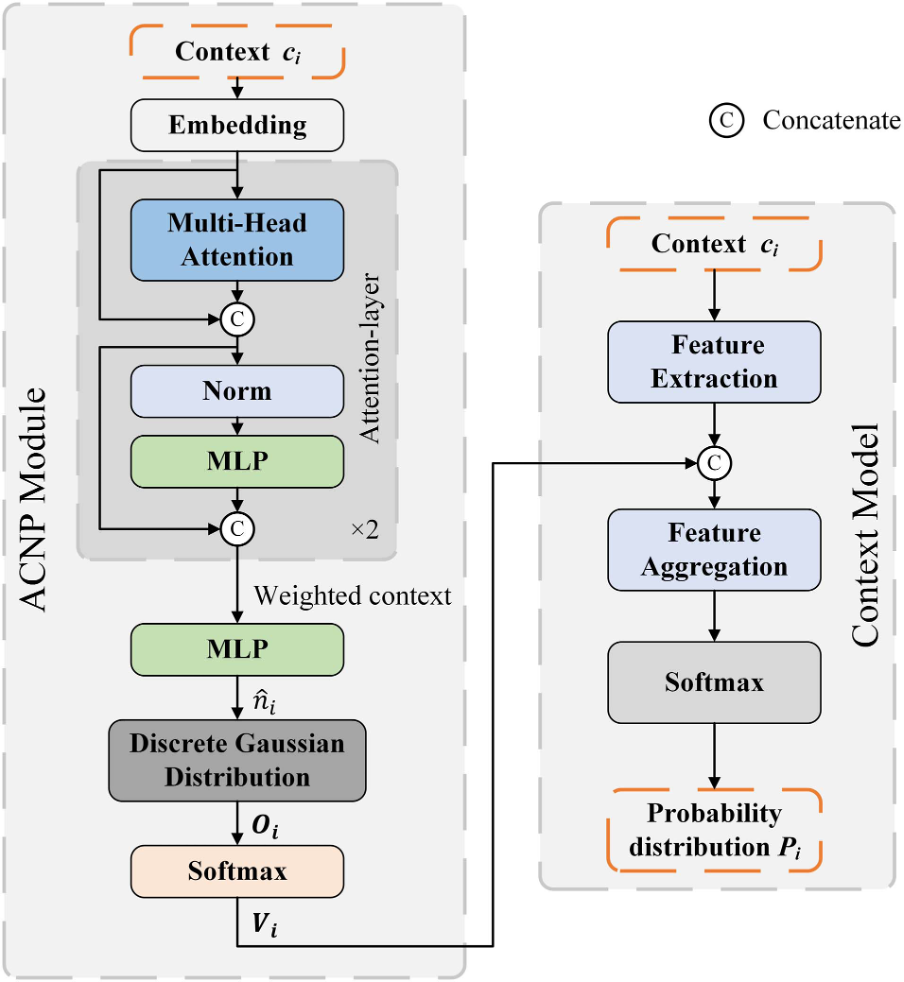
2) We introduce an attention-based child node number prediction (ACNP) module to predict the number of occupied child nodes and map it into an 8-dimensional vector containing the information about the number of occupied child nodes. The resulting 8-dimensional vector then serves as a feature to assist in training the context model.
Figure 2: Overall architecture of the ACNP module.
To verify the efficiency of the proposed ACNP module, we used it to enhance OctAttention [1] and OctSqueeze [2]. The resulting models are named as ACNP-OctAttention and ACNP-OctSqueeze, respectively. To validate their performance, we compared ACNP-OctAttention with OctAttention and EM-OctAttention [3], and compared ACNP-OctSqueeze with OctSqueeze. Experimental results showed that ACNP significantly improved the coding efficiency of two octree-based context models: OctAttention and OctSqueeze. However,ACNP increased the complexity of the context models.
Reference: [1] C. Fu, G. Li, R. Song, W. Gao, and S. Liu, “OctAttention: Octree-based large-scale contexts model for point cloud compression,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 625–633. [2] L. Huang, S. Wang, K. Wong, J. Liu, and R.Urtasun, “OctSqueeze: Octree structured entropy model for LiDAR compression,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 1313–1323. [3] C. Sun, H. Yuan, S. Li, X. Lu, and R. Hamzaoui, “Enhancing context models for point cloud geometry compression with context feature residuals and multi-loss,” IEEE Trans. Emerg. Sel. Topics Circuits Syst., vol. 14, no. 2, pp. 224–234, Jun. 2024,
In July 2024, the research paper titled “Optimized Quantization Parameter Selection for Video-based Point Cloud Compression”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, and others from Shandong University and De Montfort University, in collaboration with Prof. Ferrante Neri, Dr Linwei Zhu, Prof. Yun Zhang from the University of Surrey, Chinese Academy of Sciences (CAS), China, and Sun Yat-sen University, China, was accepted for publication in Frontiers in Signal Processing. This paper focuses on optimized algorithm development for video-based point cloud compression.
High-quality visualizations of point clouds often require millions of points, resulting in large storage and transmission costs, especially for dynamic point clouds. The video-based point cloud compression (V-PCC) standard generates two-dimensional videos from the geometry and colour information of the point cloud sequence. Each video is then compressed with a video coder, which converts each frame into frequency coefficients and quantizes them using a quantization parameter (QP). Traditionally, the QPs are severely constrained. The rate-distortion performance can be improved by relaxing this constraint and treating the QP selection problem as a multi-variable constrained combinatorial optimization problem, where the variables are the QPs. To solve the optimization problem, we propose a variant of the differential evolution (DE) algorithm. While DE was initially introduced for continuous unconstrained optimization problems, we adapt it for our constrained combinatorial optimization problem. Also, unlike standard DE, we apply individual mutation to each variable. Furthermore, we use a variable crossover rate to balance exploration and exploitation.
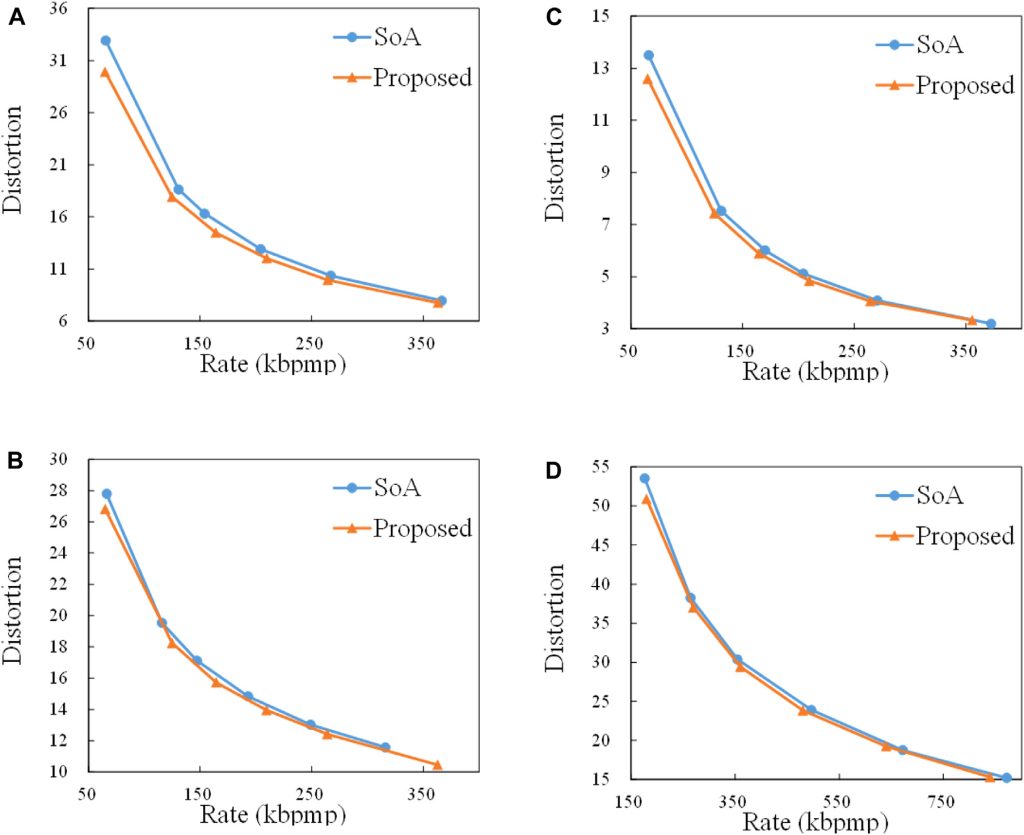
Figure 1. Comparison of the rate-distortion curves of the proposed method and the state-of-the-art method (SoA) for two GOPs. (A) Soldier, (B) Queen, (C) Loot, (D) Longdress.
Experimental results for the low-delay configuration of the V-PCC reference software show that our method can reduce the average bitrate by up to 43% compared to a method that uses the same QP values for all frames and selects them according to an interior point method.
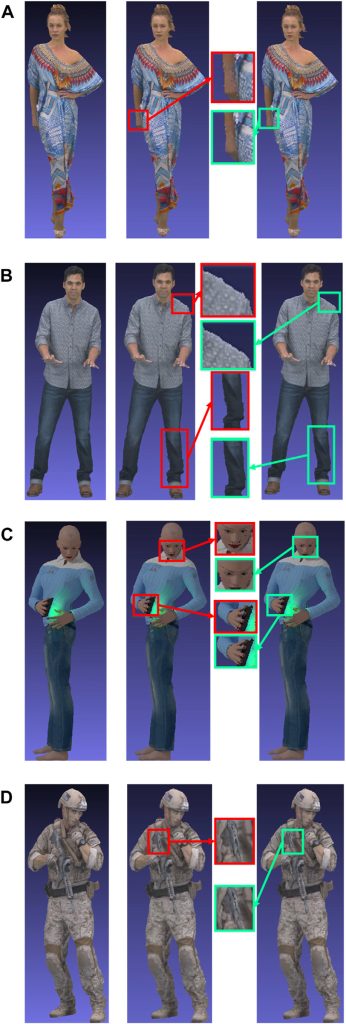
Figure 2. Visual quality comparison for one group of frames. Left: original, Middle: method in Liu et al. (2021), Right: proposed. (A) Longdress, (B) Loot, (C) Queen, (D) Soldier.
Reference: Liu, Q., Yuan, H., Hou, J., Hamzaoui, R., and Su, H. (2021). Model-based joint bit allocation between geometry and color for video-based 3d point cloud compression. IEEE Trans. Multimedia 23, 3278–3291.
In February 2024, the research paper titled ” Enhancing context models for point cloud geometry compression with context feature residuals and multi-loss”, co-authored by the project participants – Prof. Hui Yuan, Dr Xin Lu, Mr Chang Sun and others from Shandong University and De Montfort University, was accepted for publication in IEEE Journal on Emerging and Selected Topics in Circuits and Systems. This paper focuses on the development of a general method to enhance context models for geometry point cloud compression. In point cloud geometry compression, context models usually use the one-hot encoding of node occupancy as the label, and the cross-entropy between the one-hot encoding and the probability distribution predicted by the context model as the loss function. However, this approach has two main weaknesses. First, the differences between contexts of different nodes are not significant, making it difficult for the context model to accurately predict the probability distribution of node occupancy. Second, as the one-hot encoding is not the actual probability distribution of node occupancy, the cross-entropy loss function is inaccurate. To address these problems, we propose a general structure that can enhance existing context models rather than proposing a special network. (1) To enhance the differences between contexts, we propose to include context feature residuals of adjacent contexts into the context models. Furthermore, we use the cosine similarity and the Euclidean distance to calculate the inter-class differences in context.
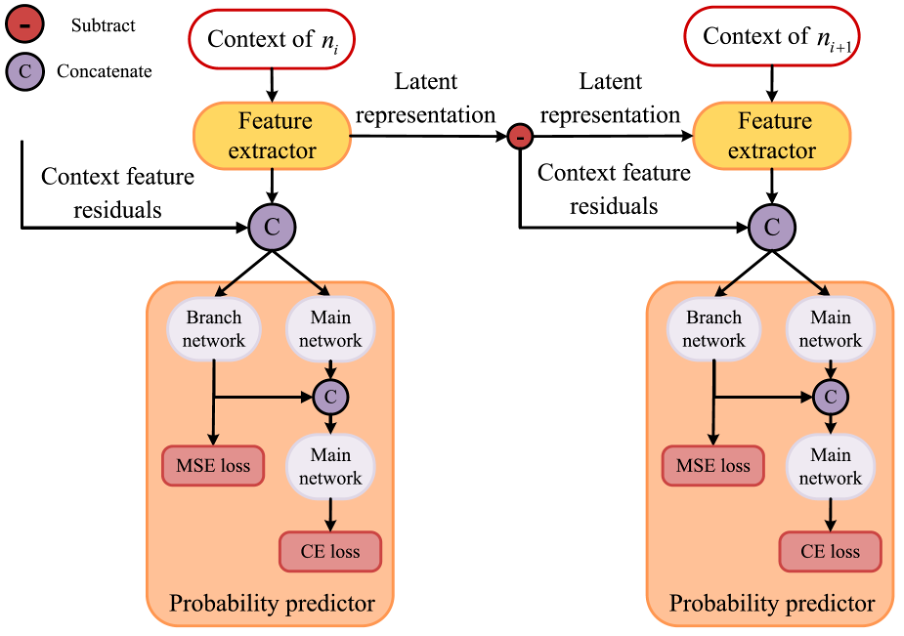
Figure 1: Overall architecture of the proposed structure. The structure consists of a feature extractor, main network, branch network, concatenate module and subtract module. Among them, the feature extractor and main network form the original context model. The subtract module is used to calculate context feature residuals and the concatenate module is used to concatenate the input of the network.
(2) We improve the performance of the context models by adding an MLP branch that directly predicts the node occupancy instead of the probability distribution. The loss function of this branch is the mean squared error (MSE) between its output and the actual node occupancy. Since the node occupancy is an accurate label, this branch introduces accurate gradients during the training of the context model. At the same time, the output of this branch will also serve as a feature to assist the training of the main network.
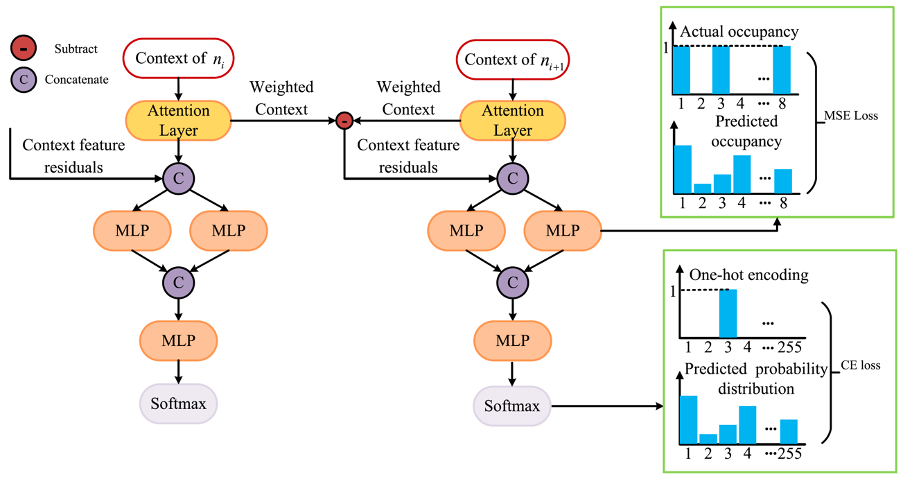
Figure 2: Overall architecture of EMR-OctAttention. The weighted context output from the attention layer is used as a latent representation to calculate the context feature residuals. The context feature residuals are concatenated with the weighted context and fed into two MLPs. One MLP outputs a 255-dimensional probability distribution and is the main network. The cross-entropy between this probability distribution and the one-hot encoding representing the actual occupancy of the node is used as the loss function. The other MLP outputs an 8-dimensional vector representing the occupancy probability of each child node. The mean squared error between this 8-dimensional vector and the actual occupancy of the 8 child nodes is used as the loss function.
The effectiveness of our proposed approach is demonstrated by applying it to two state-of-the-art models: an octree-based one (OctAttention [1]) and a voxel-based one (VoxelDNN [2]). Experimental results show that our method can reduce the bitrate in geometry point cloud encoding without significantly increasing time complexity.
Reference: [1] C. Fu, G. Li, R. Song, W. Gao, and S. Liu, “OctAttention: Octree-based large-scale contexts model for point cloud compression,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 625–633. [2] D. T. Nguyen, M. Quach, G. Valenzise, and P. Duhamel, “Learning-based lossless compression of 3D point cloud geometry,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Toronto, ON, Canada, Jun. 2021, pp. 4220–4224.